메타, 객체 감지를 위한 SAM 3 및 SAM 3D AI 모델 공개
페이지 정보
본문
(퍼플렉시티가 정리한 기사)
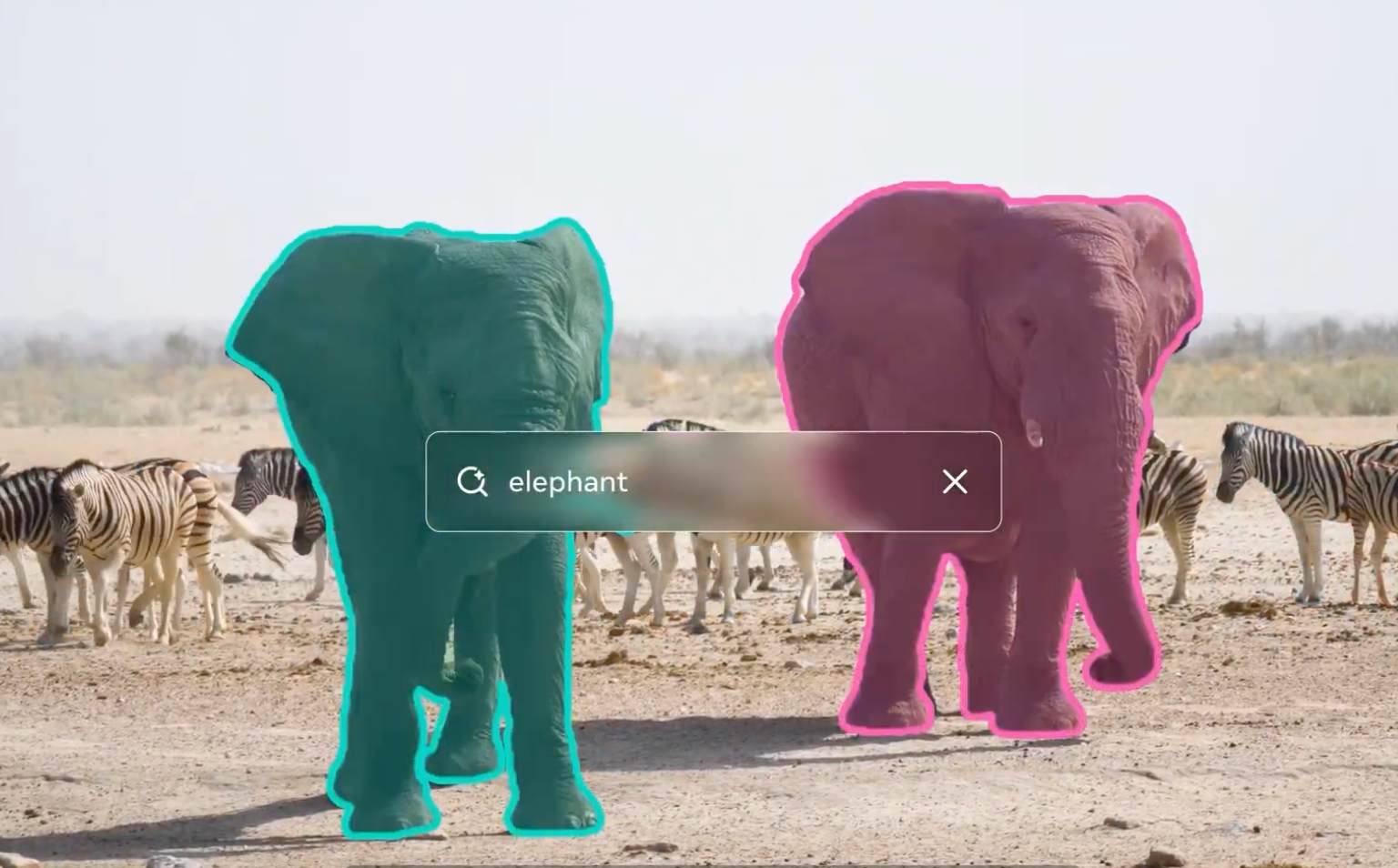
Meta Platforms, Inc.는 오늘 오픈소스 컴퓨터 비전 모델 컬렉션인 Segment Anything Collection의 최신 버전인 SAM 3와 SAM 3D를 발표했으며, 텍스트 기반 객체 감지 및 3D 재구성 기능을 도입하여 비디오 편집 및 콘텐츠 제작 워크플로우를 혁신할 것이라고 밝혔습니다.
이번 릴리스는 사용자가 수동 선택이 아닌 자연어 프롬프트를 사용하여 객체를 감지하고 분할할 수 있도록 함으로써 이전 Segment Anything 모델과는 다른 방향을 제시합니다. Meta의 발표에 따르면, SAM 3는 "노란색 스쿨버스" 또는 "빨간 야구모자를 쓰지 않고 앉아 있는 사람들"과 같은 텍스트 문구로 설명된 객체의 모든 인스턴스를 식별할 수 있습니다. SAM 3D는 단일 이미지에서 객체, 사람 및 장면의 3차원 모델을 재구성합니다.
텍스트 프롬프트와 향상된 정확도
SAM 3는 Meta의 연구 논문에 따르면 LVIS 벤치마크에서 47.0의 제로샷 마스크 평균 정밀도를 달성하여 기존 시스템 대비 22% 향상된 성능을 나타냅니다. 이 모델은 H200 GPU에서 프레임당 약 30밀리초로 이미지를 처리하며 동시에 100개 이상의 객체를 처리합니다.
Meta는 발표에서 "SAM 3는 이러한 제한을 극복하여 훨씬 더 광범위한 텍스트 프롬프트를 수용합니다"라고 밝혔습니다. 회사는 Roboflow와 협력하여 개발자들이 특정 애플리케이션을 위해 데이터에 주석을 달고, 미세 조정하며, SAM 3를 배포할 수 있도록 했습니다.
메타 제품 전반에 걸친 즉각적인 통합
Meta는 이미 자사의 제품 생태계 전반에 두 모델을 배포하고 있습니다. SAM 3는 회사의 Edits 비디오 제작 앱과 Vibes 플랫폼에서 새로운 효과를 지원하여, 크리에이터들이 콘텐츠 내 특정 객체에 수정을 적용할 수 있도록 합니다. SAM 3D는 Facebook Marketplace의 새로운 "방에서 보기" 기능을 구현하여, 사용자들이 구매 전에 가구 및 홈 데코 아이템을 자신의 공간에서 시각화할 수 있도록 돕습니다.
두 모델 모두 Meta의 새로운 Segment Anything Playground 플랫폼을 통해 접근할 수 있으며, 기술적 전문 지식이 필요하지 않습니다. Meta는 SAM 3 모델 가중치, 평가 벤치마크 및 연구 논문을 공개하고 있으며, SAM 3D 모델 체크포인트와 추론 코드는 연구 커뮤니티와 공유되고 있습니다.